
Retrieval-Augmented Generation Makes AI Smarter
Real-time augmented-data retrieval can significantly boost the accuracy and performance of generative AI. However, mastering this enhancement can be quite challenging.
A fundamental issue with artificial intelligence is its artificiality. Generative AI systems and large language models (LLMs) employ statistical methods instead of intrinsic knowledge to forecast text outcomes. Consequently, they sometimes generate falsehoods, errors, and unrelated hallucinations.
This deficiency in real-world knowledge bears repercussions that affect various domains and industries. The consequences can be particularly severe in sectors like finance, healthcare, law, and customer service, leading to poor business decisions, disgruntled customers, and financial losses.
Organizations are increasingly embracing retrieval-augmented generation (RAG) to tackle these challenges. According to a report from Deloitte, over 70% of enterprises now implement this framework to enhance LLMs. “It is essential for realizing the full benefits of AI and managing costs,” states Jatin Dave, managing director of AI and data at Deloitte.
RAG’s allure lies in its ability to facilitate faster and more reliable decision-making. It also enhances transparency and energy efficiency. As the competitive business environment becomes more intense and AI emerges as a key differentiator, RAG is becoming a vital tool in the AI toolkit.
Scott Likens, US and Global Chief AI Engineering Officer at PwC, notes, “RAG is revolutionizing AI by combining the precision of retrieval models with the creativity of generative models.”
The Strength of RAG in AI
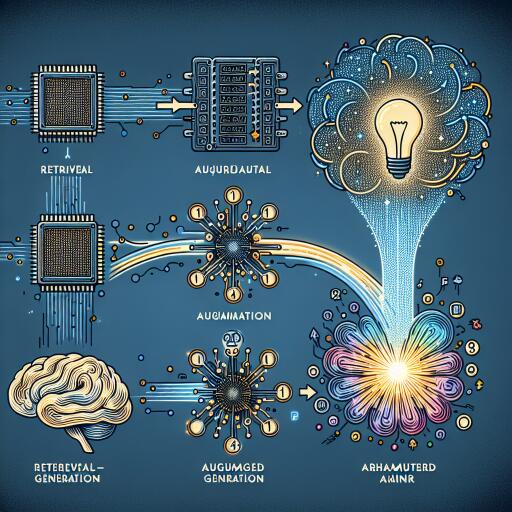
The true power of RAG resides in its ability to merge a trained generative AI system with real-time data, usually sourced from an independent database. “This synergy enhances everything from customer support to content personalization, offering more accurate and context-aware interactions,” Likens explains.
RAG boosts the chances of delivering accurate and timely results by verifying external sources before responding to a query. It also provides greater transparency by generating links that humans can check for verification. Additionally, RAG reduces the time required to retrieve information, lowers compute overhead, and conserves energy.
“RAG enables the search through a vast number of documents without connecting to the LLM during the search process,” Dave points out. “A RAG search is also faster than an LLM processing tokens, resulting in quicker response times from the AI system.”
This capability makes RAG especially valuable for handling diverse data types from various sources, including product catalogs, technical images, call transcripts, policy documents, marketing data, and legal contracts. The technology is rapidly evolving, with RAG becoming better equipped to handle larger datasets and operate within complex cloud frameworks.
For instance, RAG can integrate generalized medical or epidemiological data housed within an LLM with specific patient data to provide more accurate and personalized recommendations. It can link a customer using a chatbot with an inventory system or third-party logistics data to offer up-to-date information about a delayed shipment. It also enables the personalization of marketing and product recommendations based on past behaviors.
Implementing RAG Effectively
The result is a higher degree of personalization and contextualization. “RAG can tailor language model outputs to specific enterprise knowledge and enhance the core capabilities of LLMs,” says Likens. Nonetheless, this innovation does not come without its challenges. “RAG adds complexity to knowledge management. It involves managing data lineage, multiple versions of the same source, and dispersed data across diverse business units and applications,” he adds.
Designing an effective RAG framework can be complicated. Likens emphasizes that, on the technological front, several foundational components are essential. These include vector databases, orchestration, a document processing tool, and a scalable data processing pipeline.
Likens also highlights the importance of leveraging tools that streamline RAG development and augment the accuracy of information. This includes hybrid retrieval solutions, experiment tracking, and data annotation tools. More sophisticated tools, such as LLMs, vector databases, and compute workflow tools, are usually offered by hyperscalers and SaaS providers.
“There is not a one-size-fits-all RAG pipeline, so there will always be a need to tailor the technology to the specific use case,” Likens emphasizes.
Navigating the Challenges of RAG
Another crucial step is establishing an integrated data and information pipeline. Chunking — breaking data into smaller strings that an LLM can process — is vital. Additionally, there is a need to fine-tune the language model for contextually interpreting RAG data and to modify its weights during post-training procedures.
“People typically focus on the LLM model, but it’s the database that often causes the most problems because, unlike humans, LLMs aren’t good with domain knowledge,” asserts Ben Elliot, research vice president at Gartner. “A person reads something and understands it makes sense, even without grasping every detail.”
Elliot continues that paying attention to metadata and retaining human oversight is crucial. This often involves tasks such as rank ordering and grounding, which root a system in reality — thereby increasing the likelihood of producing meaningful and context-aware AI outputs. Although achieving 100% accuracy with RAG is impossible, the correct mix of technology and processes — including employing footnoting for human review — enhances the likelihood that an LLM will deliver value.
There’s no singular approach to RAG. It’s necessary to experiment, as a system may initially fail to produce accurate information for valid reasons, Likens suggests. Additionally, monitoring data biases and ethical implications, especially concerning data privacy, is critical. The risks associated with unstructured data are significant, particularly if it contains personally identifiable information (PII) or other sensitive details.
Organizations that successfully navigate these challenges elevate LLMs to a more functional and effective level. They accomplish more with fewer resources, translating into a more agile and flexible Generative AI framework with reduced fine-tuning needs. “RAG equals the playing field between ultra-large language models exceeding 100 billion parameters and more compact models ranging from 8 to 70 billion parameters… organizations can achieve comparable results with minimal performance trade-offs.”
Of course, RAG is not a panacea. It cannot transform an average LLM into a revolutionary force, Dave acknowledges. Furthermore, much business knowledge is not encapsulated in digital documents, which means an overreliance on the technology could be problematic. However, “Semantic search is very powerful,” he concludes. In the coming years, “RAG-based constructs will become a key component of the technology stack in every enterprise.”